Submitted to the Journal of Risk and Financial Management
Separating Backtest Profitability from Entry-Timing Skill
A structure-preserving randomization test that isolates entry-placement skill from structural market exposure in trading rules.
Aryan Patel · 2026
Read the full paper (PDF)Abstract
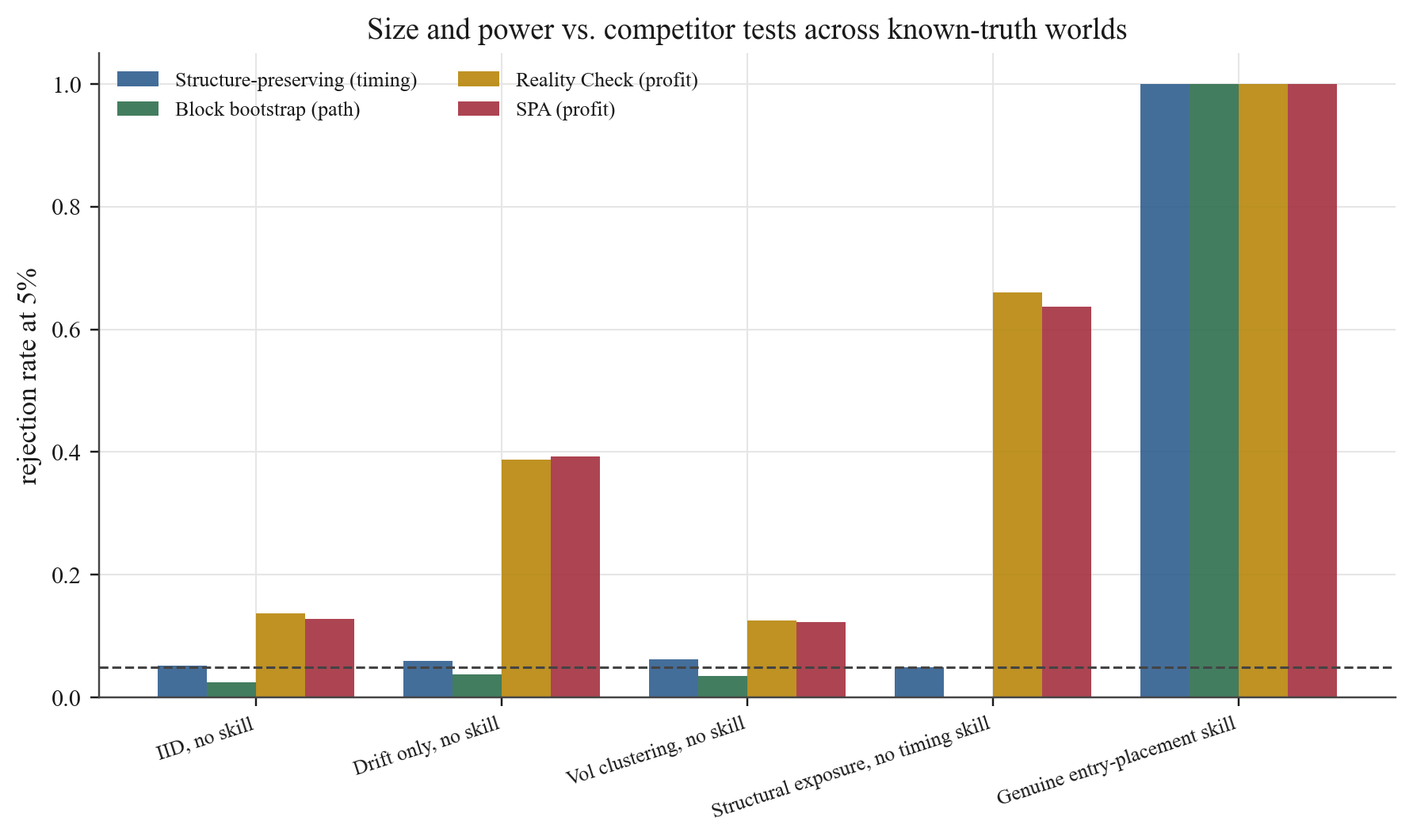
Profitable trading rules can earn returns through market exposure without adding value through entry timing. This paper evaluates that distinction with a structure-preserving randomization test: conditional on a declared placement law, the realized trade structure and price path are held fixed while only the calendar placement of trades is re-randomized. Under the sharp null that the realized placement is exchangeable with those re-placements, the plus-one Monte Carlo p-value is finite-sample valid and measures whether the observed schedule is unusually favorable relative to structurally matched alternatives. In synthetic worlds, White's Reality Check and Hansen's SPA reject a profitable-but-untimed exposure strategy about two-thirds of the time (0.660 and 0.637), while the placement test holds nominal size (0.050) and retains power against genuine timing. On an eleven-rule gold-futures panel and a 322-test cross-asset scan, profitability is common but no rule shows robust, measure-invariant entry-placement skill after multiplicity control. The result is not a claim that the rules are unprofitable; it is evidence that the timing component should not be priced as active skill without clearing a structure-matched counterfactual.
Key findings
- 01
Profitability and timing skill are distinct. Reality Check and SPA reject profitable-but-untimed strategies about 66% of the time by design (they measure profitability), while the placement test holds its 5% nominal size on the same strategies, isolating the timing question.
- 02
A conditional randomization test that holds trade structure (ordered durations, sizes, directions, non-overlap) and the price path fixed while re-randomizing only calendar placement, giving finite-sample-valid p-values with no distributional assumptions on returns.
- 03
Model risk is made explicit through a declared family of re-randomization measures (neutral gap-permutation, leading-gap restriction, context-matched, volatility-regime-preserving), reported as a sensitivity range rather than a single favored choice.
- 04
Gold-futures evidence (2002 to 2026, eleven rules): profitability is common (10 of 11 positive returns), but no rule clears p ≤ 0.05 under the neutral measure; the minimum p-value is 0.053 (Volatility Squeeze Breakout, N = 4 trades).
- 05
Cross-asset robustness (322 tests on 47 instruments): the 13 observed significant tests fall below the 16.1 expected by chance; zero survive Benjamini-Hochberg or Bonferroni correction, and the smallest p-value belongs to a random baseline.
- 06
Volatility-filtered rules show tentative evidence only under volatility-regime-matched nulls, which is measure-dependent and not robust to the neutral null, consistent with capturing volatility-regime awareness rather than calendar-timing skill.
Figures
How the method works
The method re-randomizes only the calendar placement of a fixed trade structure while holding the price path and trade logistics constant. Each trading rule generates a sequence of trades with specific ordered durations, position sizes, directions, and internal spacing. The placement test extracts this structure, then samples alternative placements of the same template onto the calendar via a declared re-randomization law. The realized performance is compared to the distribution of returns across these structurally identical alternatives, so structural exposure affects the observed and null distributions equally and only timing is isolated. Under the null that the realized placement is exchangeable with alternatives from the chosen measure, the plus-one Monte Carlo p-value is finite-sample valid.
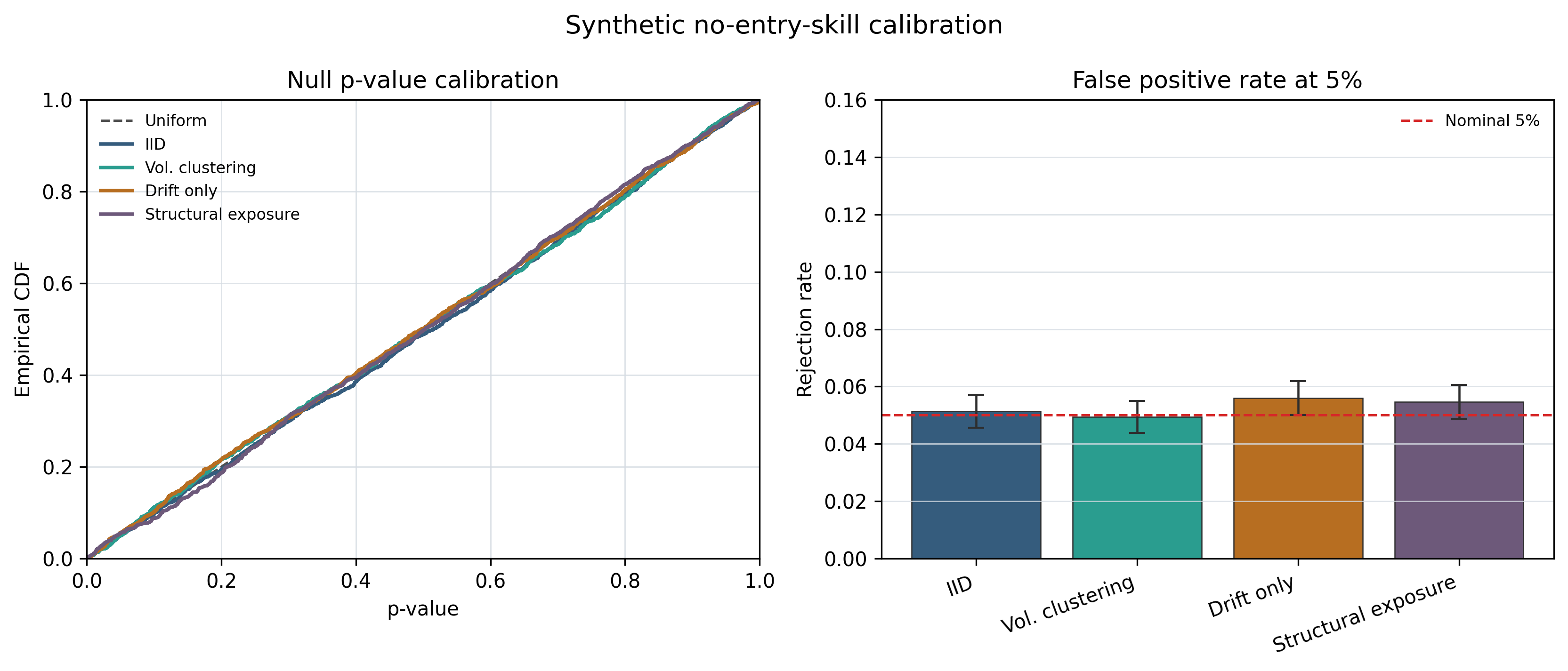
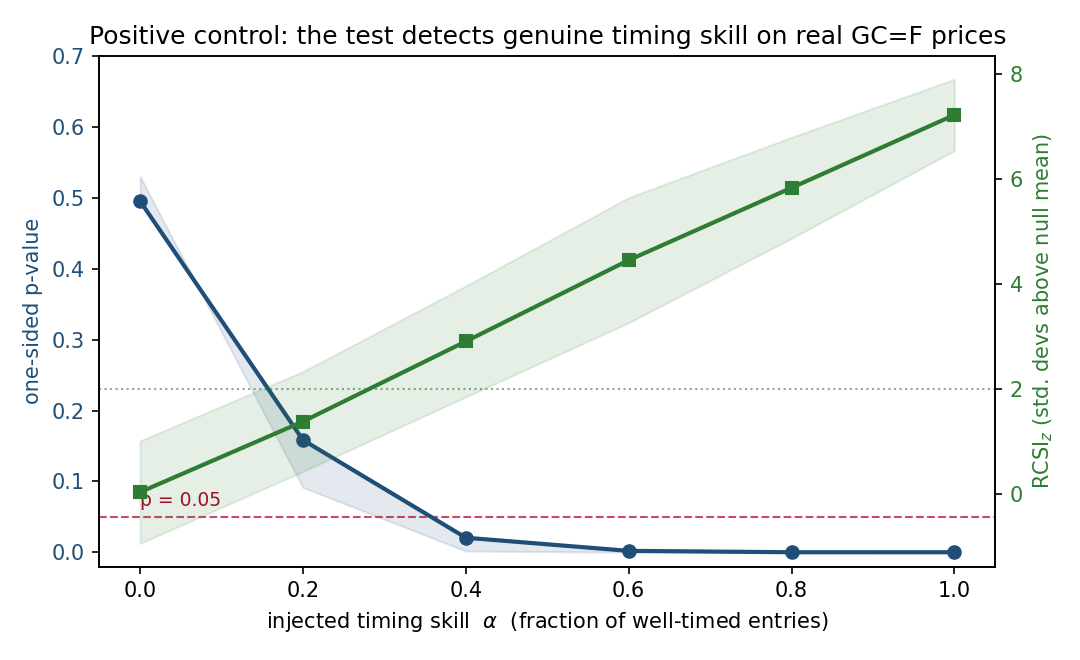
Significance testing combines Benjamini-Hochberg false-discovery-rate control, Bonferroni correction, and Kolmogorov-Smirnov uniformity checks on the p-value distribution to assess whether entry-placement skill exists after joint multiplicity control across the 322 strategy-by-asset panel. The test is calibrated on synthetic worlds with known ground truth and validated with a positive-control injection of genuine timing skill on the real gold-futures price path.
The empirical testbed spans gold futures from 2002 to 2026 and a cross-asset universe of 47 instruments at daily frequency. Eleven trading rules (trend-following, breakout, mean-reversion, and seasonal variants with a random-entry baseline) are applied unchanged to the panel without per-asset re-optimization, testing whether any rule demonstrates measure-invariant entry-placement skill under joint correction for multiple comparisons.
Data
Real data: gold futures (GC=F), daily, 2002 to 2026. Cross-asset panel: 47 instruments, 322 strategy-by-asset tests. Synthetic validation: five known-ground-truth worlds with 400 replications each, plus a positive-control injection of timing skill on real gold prices.
How to read this
- Empirical findings are primarily single-asset; the 322-test cross-asset panel is exploratory on an availability sample.
- The minimum neutral-measure p-value (0.053) is near-threshold and based on a very small trade count (N = 4).
- Non-rejection is not a claim that the rules are unprofitable; it is evidence that the timing component does not clear a structure-matched counterfactual.